数据库系统架构
1. Introduction
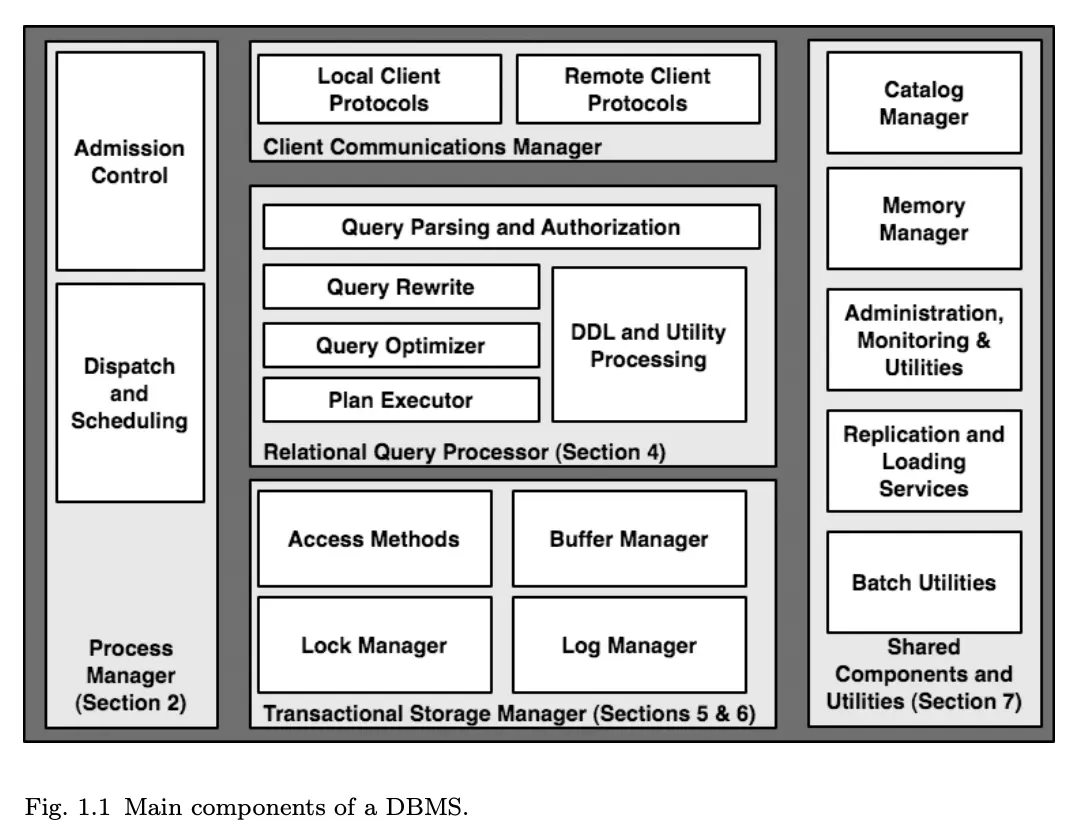
2. Process Models
3. Parallel Architecture: Process and Memory Coordination
4. Relational Query Processor
Query Parsing and Authorization
- check that the query is correctly specified,
- canonicalizes table names into a fully qualified name of the form server.database.schema.table
- convert the query into the internal format used by the optimizer(catalog manager)
- verify that the user is authorized to execute the query
Query Rewrite
The rewriter in many commercial systems is a logical component whose actual implementation is in either the later phases of query pars- ing or the early phases of query optimization. In DB2, for example, the rewriter is a stand-alone component, whereas in SQL Server the query rewriting is done as an early phase of the Query Optimizer. main responsibilities are:
- View expansion
- Constant arithmetic evaluation.
R.x < 10+2+R.yasR.x < 12+R.y. - Logical rewriting of predicates
NOT Emp.Salary > 1000000asEmp.Salary <1000000= - Semantic optimization
SELECT Emp.name, Emp.salary FROM Emp, Dept WHERE Emp.deptno = Dept.dno
Such queries can be rewritten to remove the Dept table (assuming Emp.deptno is constrained to be non-null), and hence the join. Again, such seemingly implausible scenarios often arise naturally via views.
- Subquery flattening and other heuristic rewrites
Predicate transi- tivity, for example, can allow predicates to be copied across subqueries [52].
Query Optimizer
Although Selinger’s paper is widely considered the “bible” of query optimization, it was preliminary research. All systems extend this work significantly in a number of dimensions. Among the main exten- sions are:
Plan space
The System R optimizer constrained its plan space somewhat by focusing only on “left-deep” query plans (where the right-hand input to a join must be a base table),and by “postponing Cartesian products” (ensuring that Cartesian products appear only after all joins in a dataflow). In commercial systems today, it is well known that “bushy” trees (with nested right-hand inputs) and early use of Carte- sian products can be useful in some cases. Hence both options are considered under some circumstances by most systems.
Selectivity estimation
The selectivity estimation techniques in the Selinger paper are based on simple table and index cardinalities and are na ̈ıve by the standards of current generation systems. Most systems today analyze and summarize the distributions of values in attributes via histograms and other summary statistics.
Search Algorithms
Some commercial systems, notably those of Microsoft and Tandem, discard Selinger’s dynamic pro- gramming optimization approach in favor of a goal-directed “top-down” search scheme based on the techniques used in Cascades [25]. Top-down search can in some instances lower the number of plans considered by an optimizer [82], but can also have the negative effect of increasing optimizer memory consumption. If practical success is an indication of quality, then the choice between top-down search and dynamic pro- gramming is irrelevant. Each has been shown to work well in state-of-the-art optimizers, and both still have runtimes and memory requirements that are, unfortunately, exponential in the number of tables in a query.
An educational exercise is to examine the query “optimizer” of the open-source MySQL engine, which at last check was entirely heuristic and relied mostly on exploiting indexes and key/foreign-key constraints.
Parallelism
Auto-Tuning
A variety of ongoing industrial research efforts attempt to improve the ability of a DBMS to make tuning decisions automatically. Some of these techniques are based on collecting a query workload, and then using the optimizer to find the plan costs via various “what-if” analyses. What if, for example, other indexes had existed or the data had been laid out differently? An optimizer needs to be adjusted somewhat to support this activity efficiently, as described by Chaudhuri and Narasayya [12]. The Learning Optimizer (LEO) work of Markl et al. [57] is also in this vein.
Query Executor
Most modern query executors employ the iterator model that was used in the earliest relational systems. Iterators are most simply described in an object-oriented fashion.
class iterator { iterator &inputs[]; void init(); tuple get_next(); void close(); }Where’s the Data?
In practice, each iterator is pre-allocated a fixed number of tuple descrip- tors, one for each of its inputs, and one for its output. A tuple descriptor is typically an array of column references, where each column reference is composed of a reference to a tuple somewhere else in memory, and a column offset in that tuple. The basic iterator superclass logic never allocates memory dynamically. This raises the question of where the actual tuples being referenced are stored in memory.
Access Methods
Access methods are the routines that manage access to the various disk-based data structures that the system supports. These typically included unordered files (“heaps”), and various kinds of indexes. All major commercial systems implement heaps and B+-tree indexes. Both Oracle and PostgreSQL support hash indexes for equality lookups. Some systems are beginning to introduce rudimentary support for multi-dimensional indexes such as R-trees [32]. PostgreSQL supports an extensible index called the Generalized Search Tree (GiST) [39], and currently uses it to implement R-trees for multi-dimensional data, and RD-trees for text data [40]. Systems that target read-mostly data warehousing workloads often include specialized bitmap variants of indexes as well [65],
Standard Practice
In the open source arena, PostgreSQL has a reasonably sophisti- cated query processor with a traditional cost-based optimizer, a broad set of execution algorithms, and a number of extensibility features not found in commercial products. MySQL’s query processor is far simpler, built around nested-loop joins over indices. The MySQL query optimizer focuses on analyzing queries to make sure that common operations are lightweight and efficient — particularly
- key/foreign-key joins,
- outer-join-to-join rewrites,
- and queries that ask for only the first few rows of the result set. It is instructive to read through the MySQL manual and query processing code and compare it to the more involved traditional designs, keeping in mind the high adoption rate of MySQL in practice, and the tasks at which it seems to excel.
5. Storage Manager
两种管理方式:
- 直接与底层的快设备打交道
- 通过 OS 提供的文件系统
Spatial Control
Sequential bandwidth to and from disk is between 10 and 100 times faster than random access, and this ratio is increasing.
The best way for the DBMS to control spatial locality of its data is to store the data directly to the “raw” disk device and avoid the file system entirely. This works because raw device addresses typically correspond closely to physical proximity of storage locations.
An alternative to raw disk access is for the DBMS to create a very large file in the OS file system, and to manage positioning of data as offsets in that file. The file is essentially treated as a linear array of disk-resident pages. If the file system is being used rather than raw device access, special interfaces may be required to write pages of a different size than that of the file system; the POSIX mmap/msync calls, for example, provide such support.
Temporal Control: Buffering
DBMS contains critical logic that reasons about when to write blocks to disk. Most OS file systems also provide built-in I/O buffering mechanisms to decide when to do reads and writes of file blocks. If the DBMS uses standard file system interfaces for writing, the OS buffering can confound the intention of the DBMS logic by silently postponing or reordering writes. This can cause major problems for the DBMS.
The second set of problems with OS buffering concern performance, but have no implications on correctness. Modern OS file systems typically have some built-in support for read-ahead (speculative reads) and write-behind (delayed, batched writes). These are often poorly suited to DBMS access patterns.
The final performance issues are “double buffering” and the high CPU overhead of memory copies. Copying data in memory can be a serious bottleneck. Copies contribute latency, consume CPU cycles, and can flood the CPU data cache.
This fact is often a surprise to people who have not operated or implemented a database system, and assume that main-memory oper- ations are “free” compared to disk I/O. But in practice, throughput in a well-tuned transaction processing DBMS is typically not I/O-bound. This is achieved in high-end installations by purchasing sufficient disks and RAM so that repeated page requests are absorbed by the buffer pool, and disk I/Os are shared across the disk arms at a rate that can feed the data appetite of all the processors in the system. Once this kind of “system balance” is achieved, I/O latencies cease to be the primary system throughput bottleneck, and the remaining main-memory bottlenecks become the limiting factors in the system. Memory copies are becoming a dominant bottleneck in computer architectures: this is due to the gap in performance evolution between raw CPU cycles per second per dollar (which follows Moore’s law) and RAM access speed (which trails Moore’s law significantly) [67].
Buffer Management
In order to provide efficient access to database pages, every DBMS implements a large shared buffer pool in its own memory space. The buffer pool is organized as an array of frames, where each frame is a region of memory the size of a database disk block. Blocks are copied into the buffer pool from disk without format change, manipu- lated in memory in this native format, and later written back. This translation-free approach avoids CPU bottlenecks in “marshalling” and “unmarshalling” data to/from disk; perhaps more importantly, fixed-sized frames sidestep the memory-management complexities of external fragmentation and compaction that generic techniques cause.
For full table scan access patterns, the recency of reference is a poor predictor of the probability of future reference, so OS page replacement schemes like LRU and CLOCK were well-known to perform poorly for many database access patterns [86]. A variety of alternative schemes were proposed, including some that attempted to tune the replacement strategy via query execution plan information [15]. Today, most systems use simple enhancements to LRU schemes to account for the case of full table scans.
- One that appears in the research literature and has been implemented in commercial systems is LRU-2 [64].
- Another scheme used in commercial systems is to have the replacement policy depend on the page type: e.g., the root of a B+-tree might be replaced with a different strategy than a page in a heap file. This is reminiscent of Reiter’s Domain Separation scheme [15, 75].
6. Transaction: Concurrent Control and Recovery
ACID
Roughly speaking, modern DBMSs implement isolation via a locking protocol.
- Durability is typically implemented via logging and recovery.
- Isolation and Atomicity are guaranteed by a combination of locking (to prevent visibility of transient database states), and logging (to ensure correctness of data that is visible).
- Consistency is managed by runtime checks in the query executor: if a transaction’s actions will violate a SQL integrity constraint, the transaction is aborted and an error code returned.
Serializability
Serializability is enforced by the DBMS concurrency control model. There are three broad techniques of concurrency control enforcement. These are well-described in textbooks and early survey papers [7], but we very briefly review them here:
- Strict two-phase locking (2PL).Transactions acquire a shared lock on every data record before reading it, and an exclusive lock on every data item before writing it. All locks are held until the end of the transaction, at which time they are all released atomically. A transaction blocks on a wait-queue while waiting to acquire a lock.
- Multi-Version Concurrency Control (MVCC): Transactions do not hold locks, but instead are guaranteed a consistent view of the database state at some time in the past, even if rows have changed since that fixed point in time.
- Optimistic Concurrency Control (OCC): Multiple transactions are allowed to read and update an item without blocking. Instead, transactions maintain histories of their reads and writes, and before committing a transaction checks history for isolation conflicts they may have occurred; if any are found, one of the conflicting transactions is rolled back.
Most commercial relational DBMS implement full serializability via 2PL. The lock manager is the code module responsible for providing the facilities for 2PL. In order to reduce locking and lock conflicts some DBMSs support MVCC or OCC, typically as an add-on to 2PL. In an MVCC model, read locks are not needed, but this is often implemented at the expense of not providing full serializability, as we will discuss shortly in Section 4.2.1. To avoid blocking writes behind reads, the write is allowed to proceed after the previous version of the row is either saved, or guaranteed to be quickly obtainable otherwise. The in-flight read transactions continue to use the previous row value as though it were locked and prevented from being changed. In commercial MVCC implementations, this stable read value is defined to be either the value at the start of the read transaction or the value at the start of that trans- action’s most recent SQL statement. While OCC avoids waiting on locks, it can result in higher penalties during true conflicts between transactions. In dealing with conflicts across transactions, OCC is like 2PL except that it converts what would be lock-waits in 2PL into transaction rollbacks. In scenaries where conflicts are uncommon, OCC performs very well, avoiding overly conservative wait time. With frequent conflicts, however, excessive rollbacks and retries negatively impact performance and make it a poor choice
Weak Consistency
ANSI SQL - Isolation level
Read Uncommitted
A transaction may read any version of data, committed or not. This is achieved in a locking implementation by read requests proceeding without acquiring any locks
Read Committed
A transaction may read any committed version of data. Repeated reads of an object may result in different (committed) versions. This is achieved by read requests acquiring a read lock before accessing an object, and unlocking it immediately after access.
Repeatable Read
A transaction will read only one version of committed data; once the transaction reads an object, it will always read the same version of that object. This is achieved by read requests acquiring a read lock before accessing an object, and holding the lock until end-of-transaction.
Serializable
Full serializable access is guaranteed.
Vendor provided levels
Cursor Stability
- https://jepsen.io/consistency/models/cursor-stability
- https://www.ibm.com/support/knowledgecenter/ssw_ibm_i_74/db2/rbafzcursorstability.htm
This level is intended to solve the “lost update” problem of READ COMMITTED. A transaction in CURSOR STABILITY mode holds a lock on the most recently read item on a query cursor; the lock is automatically dropped when the cursor is moved (e.g., via another FETCH) or the transaction terminates. CURSOR STABILITY allows the transaction to do read–think–write sequences on individual items without intervening updates from other transactions.
Snapshot Isolation
A transaction running in SNAPSHOT ISOLATION mode operates on a version of the database as it existed at the time the transaction began; subsequent updates by other transactions are invisible to the transaction. This is one of the major uses of MVCC in production database systems. When the transaction starts, it gets a unique start-timestamp from a monotonically increasing counter; when it commits it gets a unique end-timestamp from the counter. The transaction commits only if no other transaction with an overlapping start/end-transaction pair wrote data that this transaction also wrote. This isolation mode depends upon a multi-version concurrency implementation, rather than locking.
Read Consistency
This is an MVCC scheme defined by Oracle; it is subtly different from SNAPSHOT ISOLATION. In the Oracle scheme, each SQL statement (of which there may be many in a single transaction) sees the most recently committed values as of the start of the statement. For statements that fetch from cursors, the cursor set is based on the values as of the time it is opened. This is implemented by maintaining multiple logical versions of individual tuples, with a single transaction possibly referencing multiple versions of a single tuple. Rather than storing each version that might be needed, Oracle stores only the most recent version. If an older version is needed, it produces the older version by taking the current version and “rolling it back” by applying undo log records as needed. Modifications are maintained via long-term write locks, so when two transactions want to write the same object, the first writer “wins” and the second writer must wait for the transaction completion of the first writer before its write proceeds. By contrast, in SNAPSHOT ISOLATION the first committer “wins” rather than the first writer.